
Picture this: after decades of websites desperately trying to please Google’s algorithms, along comes a markdown file that promises to make your content irresistible to ChatGPT instead.
It’s called llms.txt, and it’s causing the sort of excitement usually reserved for a new iPhone launch – except this time, the audience is developers who get genuinely thrilled by properly structured documentation.
Here’s what’s actually happening: millions of people are now getting answers from ChatGPT, Claude, and Perplexity instead of clicking through to websites. They’re asking AI models to explain complex topics, compare products, and make recommendations – and those models are pulling information from websites that were never designed to be consumed by machines.
The premise is delightfully simple: instead of letting AI models stumble around your website like a tourist with a broken GPS, you provide them with a clearly marked map to your best content.
The question isn’t whether this trend will affect your business. It’s whether you’ll be prepared when it does.
The Context: Why Traditional Web Standards Aren’t Enough
The shift from search engines to AI-powered answers represents the most significant change in content discovery since Google’s PageRank algorithm. Yet most businesses are approaching it with the same strategies they’ve used for traditional SEO, and wondering why they’re losing visibility.
As one industry expert puts it:
“The dividing line between a ‘search [engine]’ and an ‘llm’ is barely arguable anymore. Google, Perplexity, and ChatGPT have blurred that into a very fuzzy line.” (Search Engine Land)
The implications are more profound than most businesses realise.
The Numbers Don’t Lie
The data emerging from early adopters tells a compelling story. Vercel reports that 10% of their signups now come from ChatGPT as a direct result of calculated AI optimisation efforts, not traditional SEO. This isn’t a future trend; it’s a present reality that’s accelerating rapidly.
But here’s the rub:
“Large language models increasingly rely on website information, but face a critical limitation: context windows are too small to handle most websites in their entirety”. (llmstxt.org)
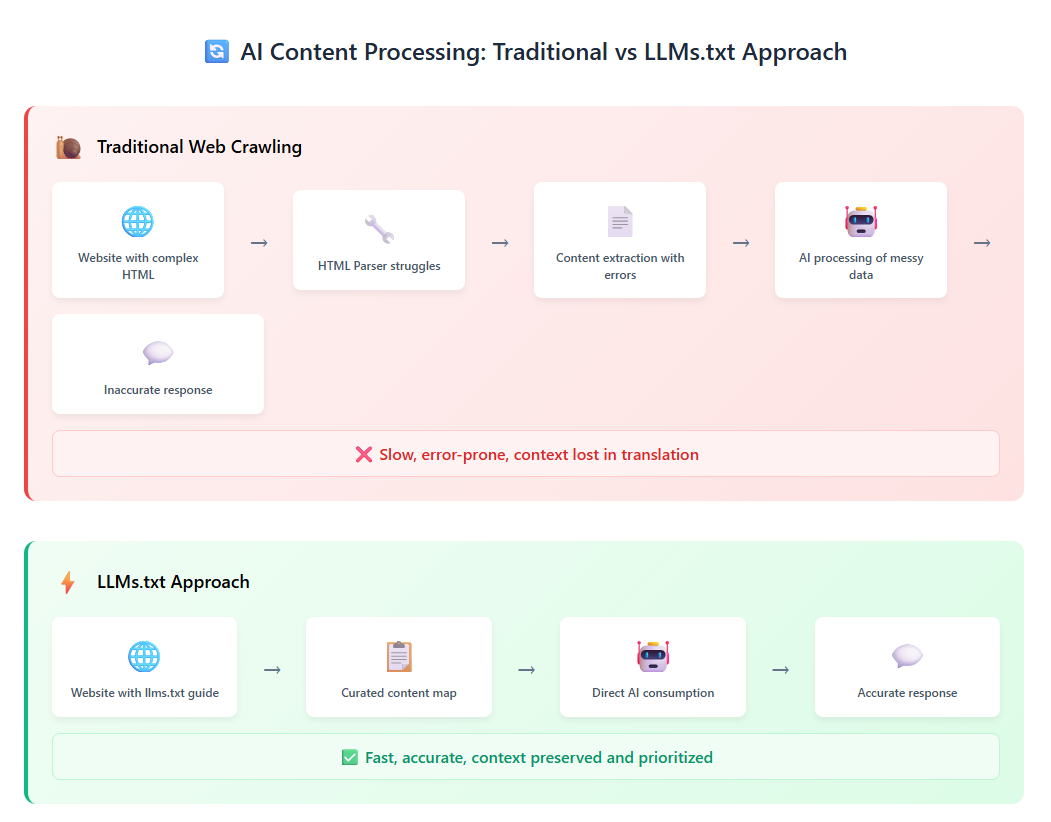
Converting complex HTML pages with navigation, ads, and JavaScript into LLM-friendly plain text is both difficult and imprecise.
Where Existing Standards Fall Short
Your website already has robots.txt and sitemap.xml files, both industry standards that have served us well for decades. But they weren’t designed for AI consumption:
- robots.txt controls what search engines can crawl, but offers no guidance on content quality or relevance.
- sitemap.xml lists all your pages, but doesn’t prioritise what’s actually important.
- Neither helps AI models understand your content hierarchy or find your most valuable information.
As one analysis puts it perfectly: “robots.txt is about exclusion. Sitemap.xml is about discovery. LLMS.txt is about curation“.

Understanding llms.txt: The Technical Foundation
Now we get to the meat of it. What exactly is llms.txt, and why are developers getting quite so excited about what is, fundamentally, just another text file?
The Anatomy of llms.txt
At its core, llms.txt is remarkably simple: a markdown file that sits at the root of your website (yoursite.com/llms.txt) and provides AI models with a curated guide to your most important content.
The specification, created by Jeremy Howard of Answer.AI, follows a specific structure:
# Project Name
> Brief project summary
Additional context and important notes
## Core Documentation
- [Quick Start](url): Description of the resource
- [API Reference](url): API documentation details
## Optional
- [Additional Resources](url): Supplementary informationThe beauty lies in its simplicity. Unlike complex RAG implementations or elaborate AI pipelines, llms.txt requires no sophisticated infrastructure. It’s just well-organised information in a format that both humans and AI models can easily understand.
The Two-File Approach
The standard actually encompasses two complementary files:
llms.txt: The curated navigation file that provides structure and highlights priority content. Think of it as the executive summary for AI consumption.
llms-full.txt: A comprehensive file containing your entire documentation in a single, consumable format. This is where the real magic happens – “a lightweight summary of your most important content, structured in a way that’s easy for LLMs to read – without the clutter of HTML, JavaScript, or advertisements”. (Mintlify)
Real-World Implementation: The FastHTML Example
Jeremy Howard’s own FastHTML project serves as the canonical example of proper llms.txt implementation:
# FastHTML
> FastHTML is a python library which brings together Starlette,
> Uvicorn, HTMX, and fastcore's `FT` "FastTags" into a library
> for creating server-rendered hypermedia applications.
Important notes:
- Although parts of its API are inspired by FastAPI, it is *not*
compatible with FastAPI syntax
- FastHTML is compatible with JS-native web components and any
vanilla JS library, but not with React, Vue, or Svelte
## Docs
- [FastHTML quick start](https://answerdotai.github.io/fasthtml/tutorials/quickstart_for_web_devs.html.md): A brief overview of many FastHTML features
- [HTMX reference](https://raw.githubusercontent.com/path/reference.md): Brief description of all HTMX attributes
## Examples
- [Todo list application](https://raw.githubusercontent.com/path/adv_app.py): Detailed walk-thru of a complete CRUD app
## Optional
- [Starlette documentation](https://gist.githubusercontent.com/path/starlette-sml.md): Subset of Starlette docs useful for FastHTML developmentNotice the clear hierarchy, descriptive link text, and strategic use of the “Optional” section for secondary resources.
The Competitive Landscape: RAG, CAG, and llms.txt
Before we dive deeper into business implications, it’s worth understanding where llms.txt fits in the broader system of AI content strategies. Because while everyone’s talking about llms.txt, it’s not the only game in town.
Retrieval-Augmented Generation (RAG): The Current Standard
RAG has become the dominant approach for enhancing language models with external knowledge.
“RAG extends the already powerful capabilities of LLMs to specific domains or an organization’s internal knowledge base, all without the need to retrain the model”. (Amazon)
The process works like this: when a user asks a question, the system searches a database of documents, retrieves relevant information, and feeds it to the LLM alongside the query. It’s powerful, but it comes with trade-offs.
RAG Challenges:
- Retrieval latency, potential errors in document selection, and increased system complexity
- Requires sophisticated infrastructure and ongoing maintenance
- Can retrieve irrelevant or outdated documents
- Complex setup and tuning requirements
Cache-Augmented Generation (CAG): The Emerging Alternative
A newer approach called Cache-Augmented Generation (CAG) is gaining traction. Instead of retrieving documents in real time, CAG preloads all relevant content into the model’s context window and caches the results.
“CAG leverages the extended context windows of modern large language models (LLMs) by preloading all relevant resources into the model’s extended context and caching its runtime parameters”. (GitHub)
CAG Benefits:
- Reduced Latency – Eliminates real-time retrieval, enabling faster inference
- Simplified architecture
- No retrieval errors
- Consistent performance
Where llms.txt Fits
Here’s where it gets interesting: llms.txt isn’t competing with RAG or CAG – it’s complementary to both. While RAG and CAG focus on how AI systems process information, llms.txt focuses on how that information is structured and presented in the first place.
Think of it this way:
- RAG: “Let me search for relevant information to answer your question.”
- CAG: “Let me use the information I’ve already loaded to answer your question.”
- llms.txt: “Here’s exactly where to find the information you need.”
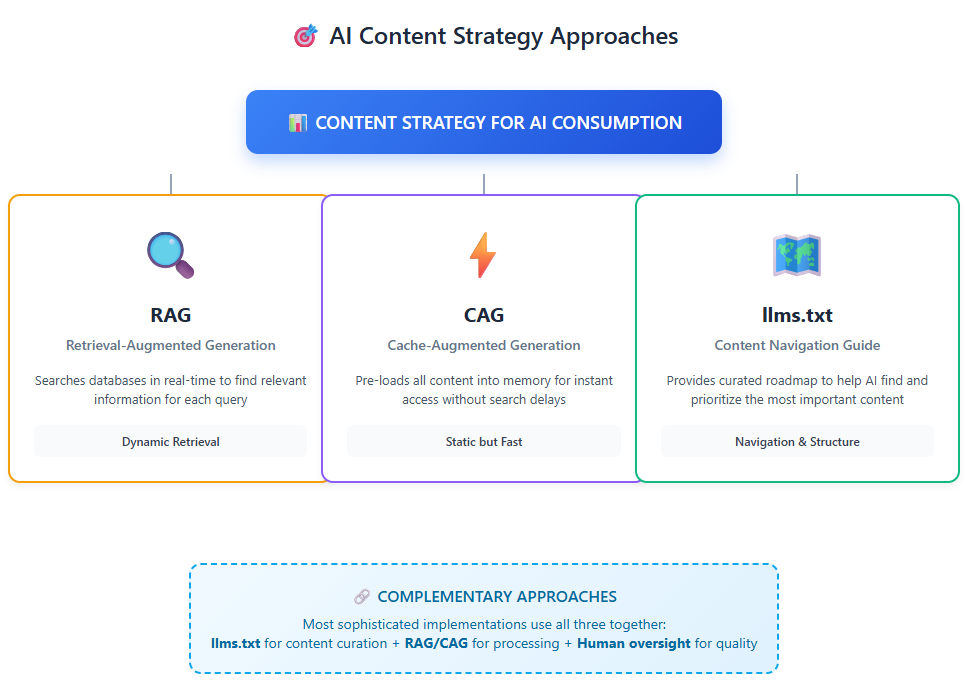
The most sophisticated implementations use all three: llms.txt to organise and prioritise content, RAG or CAG to process queries, and human oversight to ensure quality.
Industry Adoption: Early Signals and Market Reality
The story of llms.txt adoption reads like a classic tech tale: initial enthusiasm, rapid platform adoption, followed by the inevitable reality check. Let’s examine both sides.
The Success Stories
The adoption curve shifted dramatically in November 2024 when Mintlify, a major documentation platform, made a strategic decision:
“Adoption remained niche until November, when Mintlify rolled out support for /llms.txt across all docs sites it hosts. Practically overnight, thousands of docs sites – including Anthropic and Cursor – began supporting llms.txt”.
This wasn’t just a feature rollout – it was a forcing function that created critical mass almost instantly.
Notable Early Adopters:
Anthropic: Perhaps the most telling adoption signal comes from Claude’s creator. Their comprehensive llms.txt implementation organises everything from API documentation to prompt libraries in a clear hierarchy.
Cloudflare: Their implementation demonstrates how complex, multi-service companies can use llms.txt effectively, organising documentation by service area (AI Gateway, Workers, etc.).
Zapier: Focused their llms.txt around API endpoints and automation workflows, targeting their developer audience specifically.
The Skeptical Reality Check
But let’s not get carried away. The adoption story has significant holes.
Google’s John Mueller, arguably one of the most authoritative voices on web standards, offered this assessment:
“AFAIK, none of the AI services have said they’re using LLMs.TXT (and you can tell when you look at your server logs that they don’t even check for it)”.
This is the crucial point that most coverage glosses over:
“No major LLM provider currently supports llms.txt. Not OpenAI. Not Anthropic. Not Google”. (Ahrefs)
Counter-Evidence: The Monitoring Data
However, data from companies that specialise in AI optimisation tells a different story. Profound, a company specializing in tracking Generative Engine Optimization (GEO) metrics, has collected data showing that models from Microsoft, OpenAI, and others are actively crawling and indexing both llms.txt and llms-full.txt files.
The disconnect suggests something interesting: while major providers haven’t officially committed to the standard, their systems may already be experimenting with it.
Market Momentum Indicators
Beyond the adoption debates, several signals suggest llms.txt has staying power:
- Developer tooling: Integration into popular documentation platforms and development workflows
- Community growth: Active directories tracking implementations, community discussions, and tool development
- Corporate case studies: Early adopters reporting positive experiences and expanded implementations
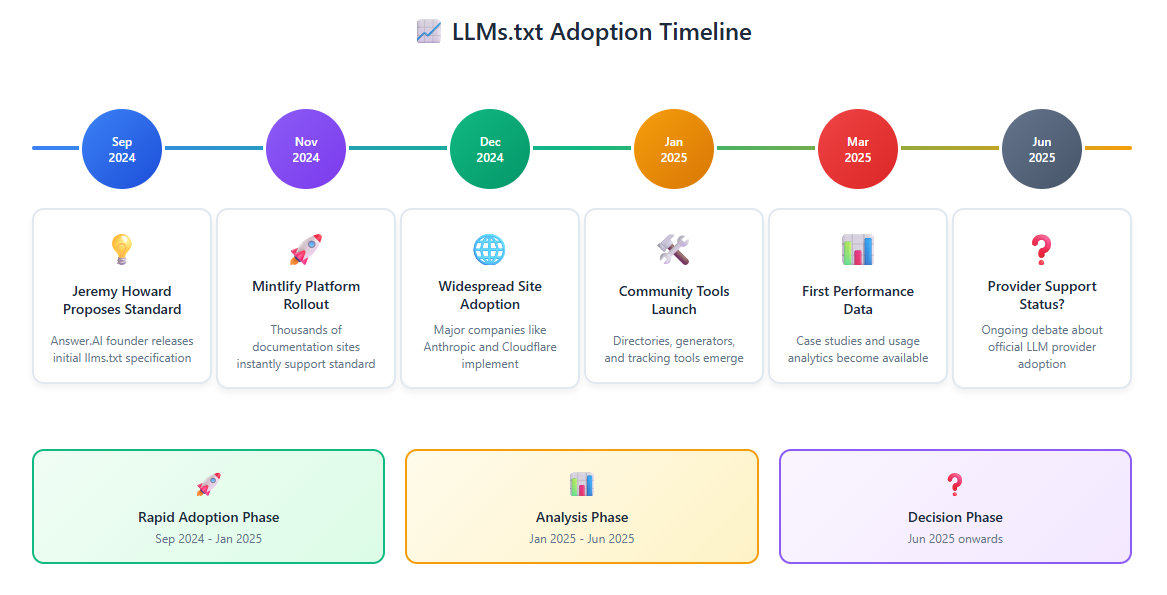
The pattern feels familiar to anyone who’s watched web standards evolve: grassroots adoption, platform integration, community momentum, followed by eventual official recognition. Whether llms.txt follows this path remains to be seen.
Strategic Business Implications
Right, let’s cut through the technical excitement and get to what actually matters: should your business care about llms.txt, and if so, what should you do about it?
The Risk-Reward Framework
The challenge with any emerging standard is balancing early-mover advantage against the risk of backing the wrong horse. With llms.txt, the calculation is unusually favourable because the downside is minimal while the potential upside is significant.
Benefits of Early Adoption:
The most compelling argument comes from recognising where content discovery is heading. “Today, being accessible to LLMs gives you a competitive advantage. Soon, it will become table stakes,” (Mintify).
Consider the implications: if your competitors’ content is easily consumable by AI models while yours requires complex parsing and interpretation, which information do you think gets cited in AI-generated responses?
Brand Control in AI Responses: “If your content isn’t in the Docs section of an llms.txt file, your brand and your narrative will not be found,” (Profound). This isn’t hyperbole – it’s a logical consequence of how AI models prioritise information consumption.
Implementation Simplicity: Unlike RAG implementations that require significant technical infrastructure, llms.txt is refreshingly straightforward. It’s a text file. The technical overhead is minimal, making it accessible to businesses of any size.
The Risks and Limitations
However, let’s not pretend this is a silver bullet.
Uncertain ROI: The most honest assessment is that we simply don’t have enough data yet. While early adopters report positive signals, comprehensive performance studies are limited. As one analysis notes: “There’s no evidence that llms.txt improves AI retrieval, boosts traffic, or enhances model accuracy”.
Standard Evolution Risk: Any emerging standard carries the risk of significant changes or being superseded entirely. The web is littered with “next big things” that never quite materialised: XHTML 2.0 was meant to revolutionise web markup but was abandoned in favour of HTML5, the Semantic Web promised machine-readable data but remains largely unfulfilled despite decades of work, and Web Components were hailed as the future of reusable HTML elements but have struggled with adoption due to complexity and browser inconsistencies.
Gaming Potential: Like early SEO, there’s a risk that llms.txt becomes a target for manipulation. The simplicity that makes it attractive also makes it vulnerable to spam and gaming. Those of us old enough to remember the Wild West days of early search optimization will recognise this pattern: what starts as a helpful signal quickly becomes a target for abuse.
We’ve seen it all before – keyword stuffing so egregious that pages read like they were written by someone having a stroke, invisible text crammed with search terms, link farms that made the yellow pages look sophisticated, and meta keywords so stuffed with irrelevant terms that “banana” somehow helped you rank for “mortgage refinancing”. The cycle is predictable: Google introduces a ranking factor, clever people exploit it, quality suffers, Google adapts, and the arms race continues.
With llms.txt, the same temptations exist: cramming irrelevant content into the “Optional” section, misleading descriptions that don’t match actual content, or creating entirely fabricated resource lists. The difference is that while Google has had decades to develop sophisticated spam detection, AI models consuming llms.txt files are still learning to distinguish signal from noise.
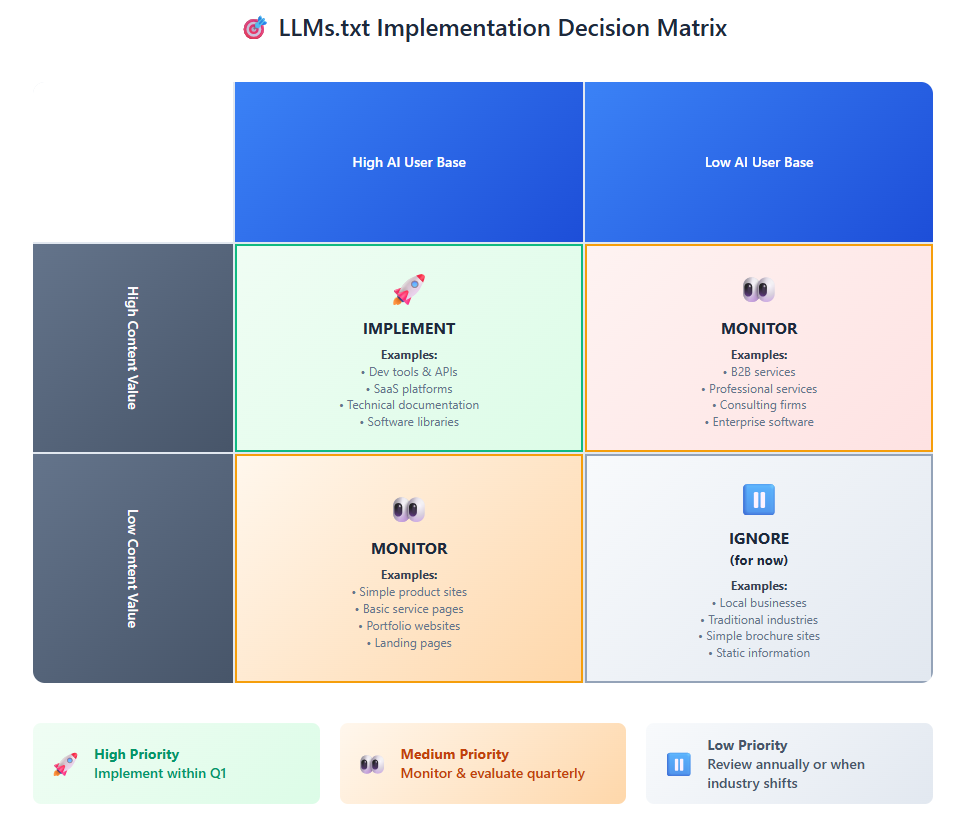
Industry-Specific Considerations
Not every business faces the same risk-reward calculation. The value of llms.txt varies significantly by industry and use case.
High-Value Sectors:
SaaS and Developer Tools: If your audience includes developers, technical decision-makers, or anyone likely to use AI tools for research, llms.txt implementation is practically mandatory. These users are already getting answers from AI models, and you want your information to be part of those responses.
Professional Services: Industries built on expertise – consulting, legal, accounting, marketing – benefit from a clear information hierarchy that helps AI models understand and cite your knowledge accurately.
E-commerce with Complex Products: If you sell products that require explanation, comparison, or detailed specification understanding, structured presentation through llms.txt can improve how AI models represent your offerings.
Caution Advised:
Highly Regulated Industries: Where content control and compliance are paramount, the uncertain adoption landscape may warrant a wait-and-see approach.
Rapidly Changing Information: If your content changes frequently or requires real-time accuracy, the static nature of llms.txt may be limiting.
Cost-Benefit Analysis
Let’s be practical about the economics:
Implementation Costs:
- Content audit and organisation: 2-5 days for most businesses
- Initial llms.txt creation: 1-2 days
- Ongoing maintenance: 2-4 hours monthly
Opportunity Costs:
- Time spent on llms.txt versus other optimisation efforts
- Potential distraction from proven strategies
Potential Returns:
- Improved AI citation rates and brand visibility
- Enhanced content discoverability in AI-powered tools
- Competitive positioning advantage during the early adoption phase
For most businesses, the cost-benefit calculation favours implementation, particularly given the minimal resource requirements.
Implementation Strategy: A Pragmatic Approach
Assuming you’ve decided llms.txt is worth pursuing, let’s discuss how to implement it without falling into common traps or over-engineering the solution.
Decision Framework Checklist
Before diving into implementation, work through this assessment to ensure you’re approaching this strategically:
Content Readiness:
- Do we have well-structured, hierarchical content worth highlighting?
- Can we clearly identify our most valuable pages and resources?
- Is our existing content organized logically, or do we need restructuring first?
Audience Alignment:
- Does our target audience use AI-powered search tools?
- Are we losing opportunities when prospects research our category using AI?
- Do our sales teams report competitors being mentioned in AI-generated comparisons?
Resource Assessment:
- Can we dedicate 1-2 weeks to initial implementation?
- Do we have someone who can work with markdown and basic web files?
- Can we commit to quarterly reviews and updates?
Strategic Fit:
- Does this align with our broader content and SEO strategy?
- Have we identified success metrics that matter to our business?
- Are we prepared to be patient with results while the standard evolves?
Implementation Phases
Rather than treating this as a one-time project, approach llms.txt as an iterative process that improves over time.
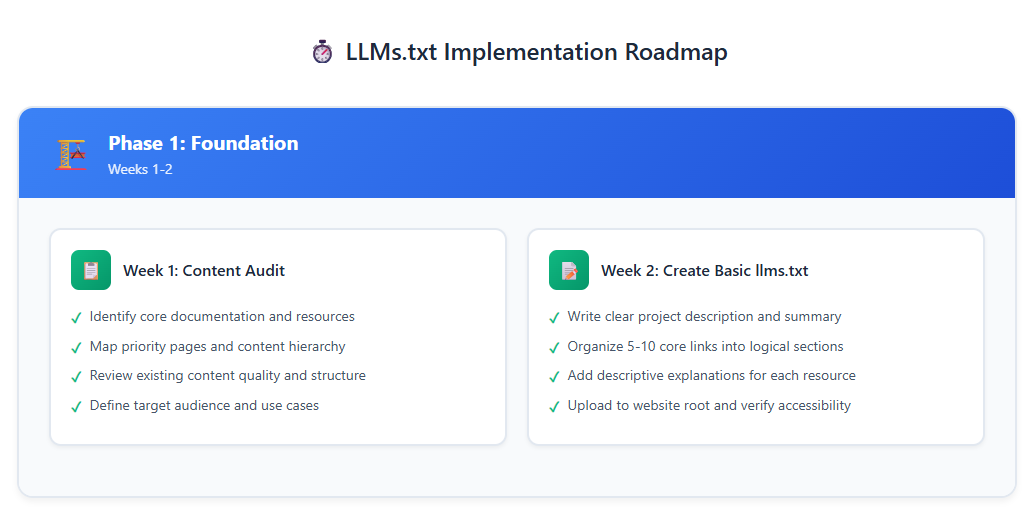
Phase 1: Foundation (Weeks 1-2)
Start with the basics and get something live quickly:
- Content Audit: Review your existing content and identify:
- Core documentation that defines your product/service
- High-performing pages that drive conversions
- Resources that prospects and customers reference frequently
- API documentation, guides, and technical resources (if applicable
- Create Basic Structure: Build your initial llms.txt with:
- Clear project/company name and description
- 5-10 core links organized into logical sections
- Brief, descriptive explanations for each link
- Strategic use of the “Optional” section for secondary resources
- Implementation: Upload the file to your website root and verify accessibility
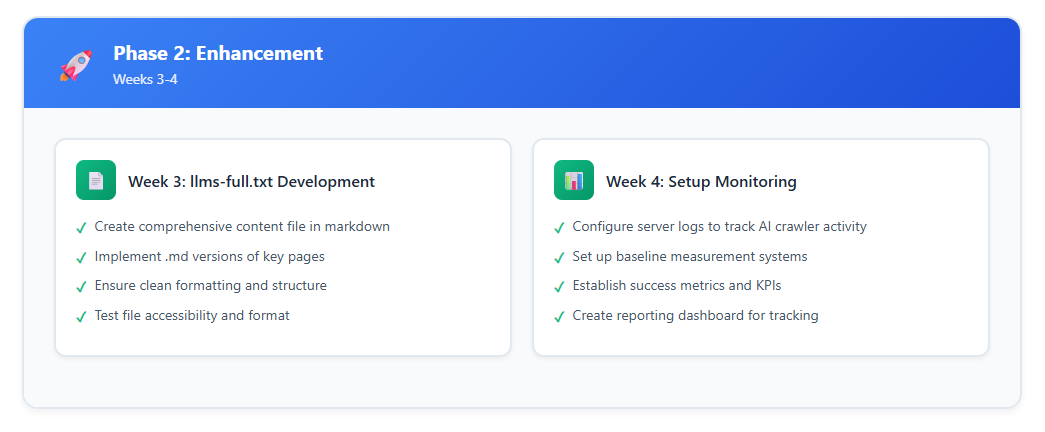
Phase 2: Enhancement (Weeks 3-4)
Once the foundation is live, expand and refine:
- Develop llms-full.txt: Create the comprehensive version that includes full content in markdown format
- Add .md Versions: Implement markdown versions of key pages (accessible by adding .md to URLs)
- Set Up Monitoring: Establish tracking for:
- AI crawler activity in server logs
- Mentions in AI-generated responses
- Traffic patterns from AI-powered sources
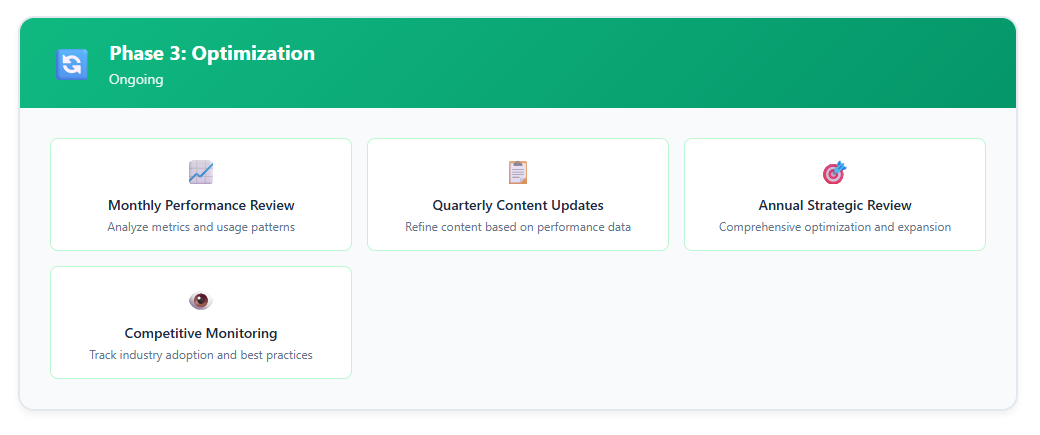
Phase 3: Optimization (Ongoing)
Transform implementation into a competitive advantage:
- Performance Analysis: Monthly review of metrics and usage patterns
- Content Refinement: Quarterly updates based on performance data and business changes
- Expansion: Gradual inclusion of additional resources based on value and performance
Integration with Existing Workflows
The key to sustainable llms.txt implementation is making it part of your normal content operations, not a separate project that gets forgotten.
Content Management Integration:
- Include llms.txt updates in your content review cycles
- Train content creators to consider AI consumption when creating new resources
- Establish clear ownership and review processes
SEO Coordination:
- Ensure llms.txt complements rather than conflicts with SEO strategy
- Use consistent messaging and positioning across traditional and AI optimization
- Coordinate keyword targeting and content themes
Technical Implementation:
- Minimal development overhead for most implementations
- Consider automation for larger content volumes
- Plan for scalability as your content library grows
Measuring Success
The challenge with any emerging standard is defining success metrics when the landscape is still evolving.
Quantitative Metrics:
- Server Log Analysis: Track requests to llms.txt and related files
- AI Citation Tracking: Monitor mentions in AI-generated responses (manual for now, automated tools emerging)
- Traffic Attribution: Identify referrals from AI-powered sources
- Search Performance: Monitor changes in traditional search visibility
Qualitative Indicators:
- Brand Mention Accuracy: How accurately do AI models represent your business?
- Competitive Positioning: Are you mentioned alongside appropriate competitors?
- Content Quality: Do AI responses highlight your most valuable information?
- Customer Feedback: Do prospects mention finding you through AI tools?
Early Warning Systems:
- Competitive monitoring to track adoption in your industry
- Regular testing of AI responses to category-related queries
- Sales team feedback on prospect research methods
The most important metric, particularly in the early stages, is simply whether AI models can find and correctly represent your most important content.
Future Outlook: Preparing for Evolution
Technology standards in the AI space evolve rapidly, and llms.txt is no exception. The question isn’t whether the landscape will change – it’s how quickly, and whether your business will be positioned to adapt.
The Technology Trajectory
The backdrop against which llms.txt operates is shifting dramatically.
“Magic.dev’s LTM-2-Mini pushes the boundaries with a staggering 100 million token context window, enabling processing of enormous datasets like entire code repositories (up to 10 million lines of code) or large-scale document collections (equivalent to 750 novels),” (Coding Landscape).
This expansion changes the fundamental value proposition of curation versus comprehensiveness. When an AI model can process the equivalent of hundreds of books in a single query, the need for carefully curated content summaries becomes less clear-cut.
The CAG Implications
The emergence of Cache-Augmented Generation as a viable alternative to RAG creates interesting possibilities for llms.txt evolution. “Just shoving everything into the context window and caching it is simpler, more efficient, and performs just as well (or better),” (Prompt Hub).
If this trend continues, llms.txt might evolve from a curation tool to a preprocessing standard, helping define how content gets cached and prioritised within expanded context windows.
Standards Evolution Signals
The most telling signal about llms.txt’s future comes from an unexpected source: Google included an llms.txt file in their new Agents to Agents (A2A) protocol. This suggests that even if current LLM providers haven’t officially committed to the standard, the underlying concept has legitimacy within the broader AI ecosystem.
Other evolution indicators to watch:
- Industry Standardization: Movement toward formal specification and governance
- Platform Integration: Built-in support from major CMS and documentation platforms
- Tool Ecosystem: Development of automated generation, monitoring, and optimization tools
- Provider Adoption: Official support statements from major LLM providers
Preparing for Multiple Scenarios
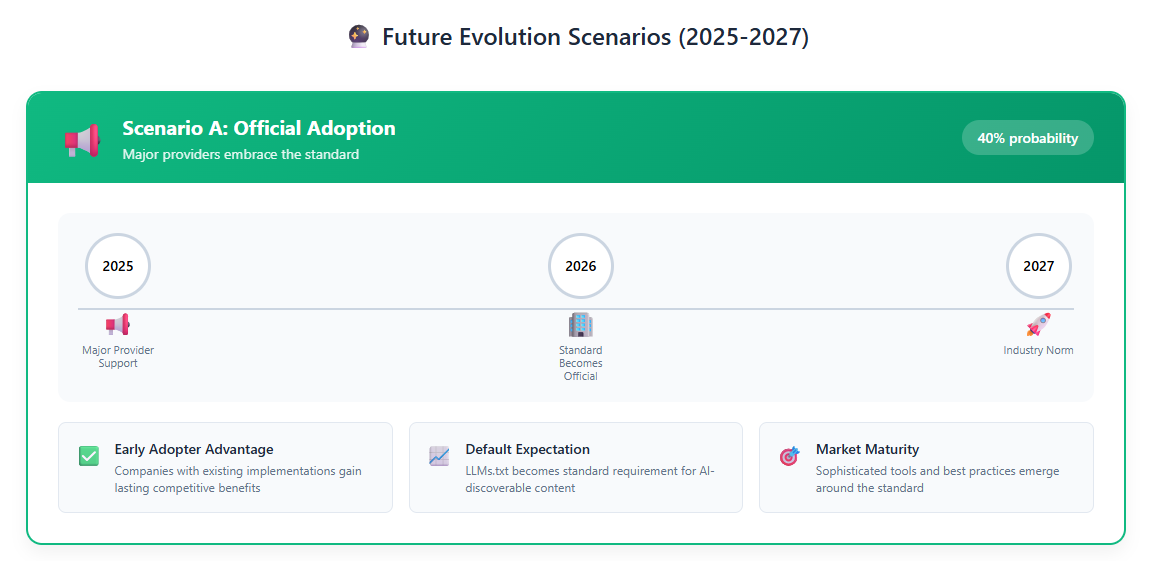
Rather than betting everything on llms.txt’s success, smart businesses prepare for multiple scenarios:
Scenario 1: Widespread Adoption
If llms.txt becomes a recognised standard with official provider support, early adopters will gain significant competitive advantages. Businesses with well-structured, comprehensive implementations will become the default sources for AI-generated responses.
Scenario 2: Evolution and Improvement
The more likely scenario involves llms.txt evolving into something more sophisticated – perhaps integrated with semantic markup, automated generation, or dynamic updating. The content structuring and curation skills developed now remain valuable even if the technical implementation changes.
Scenario 3: Alternative Standards
If competing standards emerge or existing approaches prove superior, the underlying principle – making content accessible to AI systems – remains constant. The effort invested in content organization and AI-friendly formatting transfers to whatever standard ultimately succeeds.
Strategic Positioning for Uncertainty
The key to navigating this uncertainty is maintaining flexibility while building useful capabilities:
Invest in Fundamentals: Focus on content quality, clear structure, and logical organization that benefits any AI consumption method
Stay Platform-Agnostic: Avoid lock-in to specific tools or approaches that might become obsolete
Monitor Signals: Track adoption indicators, provider statements, and competitive movements
Maintain Traditional Strategies: Don’t abandon proven SEO and content marketing approaches while experimenting with AI optimization
Conclusion and Recommendations
Let’s step back and assess what we actually know, what we can reasonably predict, and what actions make sense given the current landscape.
What We Know for Certain
AI-powered search and content discovery is not a future trend – it’s a present reality affecting millions of users daily. The traditional model of optimising content exclusively for human visitors and Google’s algorithms is increasingly insufficient.
AI models consume and process web content differently from humans or traditional search crawlers. They benefit from structure, curation, and clear hierarchies that most websites simply don’t provide.
The technical barrier to implementing llms.txt is minimal. Unlike complex AI implementations, this is fundamentally about better content organization and presentation.
What Remains Uncertain
Whether llms.txt specifically becomes the dominant standard is still an open question. The enthusiasm from developers and early adopters is promising, but official provider adoption remains limited.
While logical, the performance benefits are not yet supported by comprehensive data. Early indicators are positive, but the sample size remains small.
The evolution path for the standard itself is unclear. What we implement today may look quite different in 12-18 months.
The Pragmatic Response
Given this landscape, the most sensible approach is measured implementation with careful monitoring:
Immediate Action Items:
- Assess Current Position: Audit your content structure and identify high-value resources that would benefit from better AI accessibility
- Pilot Implementation: Start with a basic llms.txt covering your core content – treat it as an experiment, not a major project
- Establish Monitoring: Set up tracking systems to measure AI crawler activity and content mentions
- Monitor Industry Movement: Watch for adoption signals in your specific industry and competitive landscape
The Broader Strategic Imperative
While the specific mechanics of llms.txt may evolve, the underlying principle is here to stay.
This isn’t really about llms.txt. It’s about recognising that content discovery is fundamentally shifting toward AI-mediated interactions. The businesses that adapt their content strategies accordingly will maintain visibility and influence. Those that don’t risk becoming invisible in an AI-powered search landscape.
Final Perspective
The most compelling argument for llms.txt implementation isn’t the potential upside – it’s the minimal downside combined with the obvious trajectory of content consumption. Even if this specific standard doesn’t achieve universal adoption, the skills, processes, and content organisation required for implementation remain valuable.
As one industry observer noted: “LLMS.txt doesn’t contribute content to the model’s memory; it simply tells the model where to look while it’s actively generating a response”. That’s a reasonable investment in making your business discoverable in an AI-first world.
The question isn’t whether AI will reshape content discovery – it already has. The question is whether your organisation will be prepared when the shift accelerates.
Implementation Checklist:
- Audit existing content structure and quality
- Identify 5-10 highest-value pages and resources
- Create a basic llms.txt with a clear hierarchy and descriptions
- Implement monitoring for AI crawler activity
- Schedule quarterly reviews and updates
- Monitor competitive adoption and industry signals
- Maintain traditional SEO alongside AI optimization efforts
Start simple. Monitor carefully. Adapt as the landscape evolves.
And remember: the best time to prepare for change is before you’re forced to react to it.
At ScaleMath, we help businesses navigate the evolving landscape of search and content discovery. If you’re looking for strategic guidance on AI optimization, content operations, or growth strategy that puts humans in control of the technology, let’s start a conversation.