
Stellen Sie sich vor: nachdem Websites jahrzehntelang verzweifelt versucht haben, Googles Algorithmen zu gefallen, kommt nun eine Markdown-Datei, die verspricht, Ihre Inhalte stattdessen für ChatGPT unwiderstehlich zu machen.
Es heißt llms.txt und sorgt für die Art von Begeisterung, die normalerweise einem neuen iPhone-Launch vorbehalten ist – nur diesmal ist das Publikum Entwickler, die sich von korrekt strukturierter Dokumentation wirklich begeistern lassen.
Das ist es, was tatsächlich geschieht: Millionen von Menschen erhalten jetzt Antworten von ChatGPT, Claude und Perplexity, anstatt sich durch Websites zu klicken. Sie bitten KI-Modelle, komplexe Themen zu erklären, Produkte zu vergleichen und Empfehlungen abzugeben – und diese Modelle ziehen Informationen von Websites, die nie dafür konzipiert wurden, von Maschinen konsumiert zu werden.
Die Prämisse ist erfreulich einfach: Anstatt KI-Modelle wie Touristen mit einem kaputten GPS auf Ihrer Website herumirren zu lassen, stellen Sie ihnen eine klar gekennzeichnete Karte zu Ihren besten Inhalten zur Verfügung.
Die Frage ist nicht, ob dieser Trend Ihr Geschäft beeinflussen wird. Es ist vielmehr, ob Sie darauf vorbereitet sind, wenn er eintritt.
Der Kontext: Warum traditionelle Webstandards nicht mehr ausreichen
Der Wandel von Suchmaschinen zu KI-gestützten Antworten stellt die bedeutendste Veränderung in der Content-Entdeckung seit Googles PageRank-Algorithmus dar. Dennoch gehen die meisten Unternehmen mit denselben Strategien vor, die sie für traditionelles SEO verwendet haben, und wundern sich, warum sie an Sichtbarkeit verlieren.
Ein Branchenexperte formuliert es so:
„Die Trennlinie zwischen einer ‚Such[maschine]‘ und einem ‚LLM‘ ist kaum noch diskutierbar. Google, Perplexity und ChatGPT haben diese zu einer sehr unscharfen Linie verschwimmen lassen.“ (Search Engine Land)
Die Auswirkungen sind tiefgreifender, als die meisten Unternehmen erkennen.
Die Zahlen lügen nicht
Die Daten, die von Early Adopters stammen, erzählen eine überzeugende Geschichte. Vercel berichtet, dass 10 % ihrer Anmeldungen jetzt von ChatGPT stammen – als direktes Ergebnis kalkulierter KI-Optimierungsbemühungen, nicht traditioneller SEO. Dies ist kein zukünftiger Trend; es ist eine gegenwärtige Realität, die sich rasant beschleunigt.
Doch hier liegt der Haken:
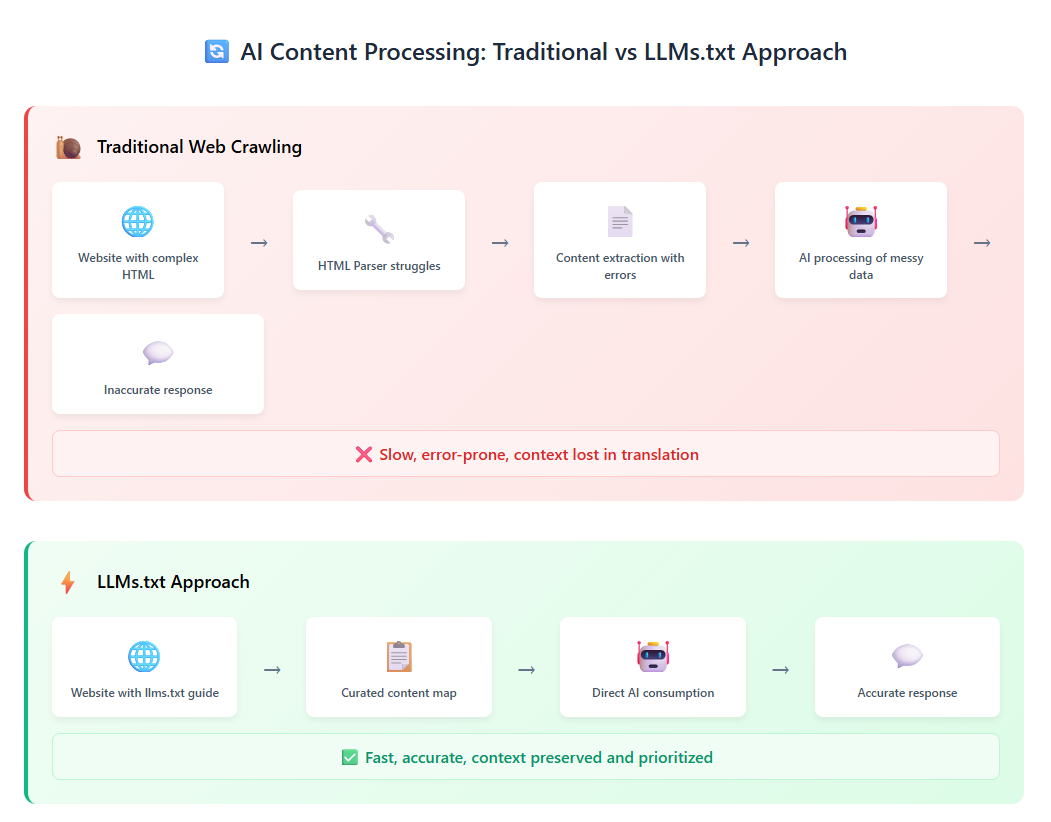
„Große Sprachmodelle verlassen sich zunehmend auf Website-Informationen, stehen jedoch vor einer entscheidenden Einschränkung: Kontextfenster sind zu klein, um die meisten Websites vollständig zu verarbeiten.“ (llmstxt.org)
Die Umwandlung komplexer HTML-Seiten mit Navigation, Werbung und JavaScript in LLM-freundlichen Klartext ist sowohl schwierig als auch unpräzise.
Wo bestehende Standards nicht ausreichen
Ihre Website verfügt bereits über robots.txt- und sitemap.xml-Dateien, beides Industriestandards, die uns seit Jahrzehnten gute Dienste leisten. Doch sie wurden nicht für den KI-Konsum entwickelt:
- robots.txt steuert, was Suchmaschinen crawlen dürfen, bietet aber keine Hinweise zur Qualität oder Relevanz von Inhalten.
- sitemap.xml listet alle Ihre Seiten auf, priorisiert aber nicht, was tatsächlich wichtig ist.
- Keines von beiden hilft KI-Modellen, Ihre Inhaltshierarchie zu verstehen oder Ihre wertvollsten Informationen zu finden.
Wie eine Analyse es treffend formuliert: „Bei robots.txt geht es um Ausschluss. Bei Sitemap.xml geht es um Entdeckung. Bei LLMS.txt geht es um Kuration.“

llms.txt verstehen: Die technische Grundlage
Kommen wir nun zum Kern der Sache. Was genau ist llms.txt, und warum sind Entwickler so begeistert von dem, was im Grunde nur eine weitere Textdatei ist?
Der Aufbau von llms.txt
Im Kern ist llms.txt bemerkenswert einfach: eine Markdown-Datei, die im Stammverzeichnis Ihrer Website (yoursite.com/llms.txt) liegt und KI-Modellen einen kuratierten Leitfaden zu Ihren wichtigsten Inhalten bietet.
Die Spezifikation, erstellt von Jeremy Howard von Answer.AI, folgt einer spezifischen Struktur:
# Project Name
> Brief project summary
Additional context and important notes
## Core Documentation
- [Quick Start](url): Description of the resource
- [API Reference](url): API documentation details
## Optional
- [Additional Resources](url): Supplementary informationDie Schönheit liegt in ihrer Einfachheit. Im Gegensatz zu komplexen RAG-Implementierungen oder aufwendigen KI-Pipelines erfordert llms.txt keine anspruchsvolle Infrastruktur. Es handelt sich lediglich um gut organisierte Informationen in einem Format, das sowohl Menschen als auch KI-Modelle leicht verstehen können.
Der Zwei-Dateien-Ansatz
Der Standard umfasst tatsächlich zwei komplementäre Dateien:
llms.txt: Die kuratierte Navigationsdatei, die Struktur bietet und prioritäre Inhalte hervorhebt. Betrachten Sie sie als die Management-Zusammenfassung für die KI-Verarbeitung.
llms-full.txt: Eine umfassende Datei, die Ihre gesamte Dokumentation in einem einzigen, konsumierbaren Format enthält. Hier geschieht die eigentliche Magie – „eine leichtgewichtige Zusammenfassung Ihrer wichtigsten Inhalte, strukturiert auf eine Weise, die für LLMs leicht lesbar ist – ohne den Ballast von HTML, JavaScript oder Werbung“. (Mintlify)
Implementierung in der Praxis: Das FastHTML-Beispiel
Jeremy Howards eigenes FastHTML-Projekt dient als kanonisches Beispiel für eine korrekte llms.txt-Implementierung:
# FastHTML
> FastHTML is a python library which brings together Starlette,
> Uvicorn, HTMX, and fastcore's `FT` "FastTags" into a library
> for creating server-rendered hypermedia applications.
Important notes:
- Although parts of its API are inspired by FastAPI, it is *not*
compatible with FastAPI syntax
- FastHTML is compatible with JS-native web components and any
vanilla JS library, but not with React, Vue, or Svelte
## Docs
- [FastHTML quick start](https://answerdotai.github.io/fasthtml/tutorials/quickstart_for_web_devs.html.md): A brief overview of many FastHTML features
- [HTMX reference](https://raw.githubusercontent.com/path/reference.md): Brief description of all HTMX attributes
## Examples
- [Todo list application](https://raw.githubusercontent.com/path/adv_app.py): Detailed walk-thru of a complete CRUD app
## Optional
- [Starlette documentation](https://gist.githubusercontent.com/path/starlette-sml.md): Subset of Starlette docs useful for FastHTML developmentBeachten Sie die klare Hierarchie, den aussagekräftigen Linktext und die strategische Nutzung des Abschnitts „Optional“ für sekundäre Ressourcen.
Die Wettbewerbslandschaft: RAG, CAG und llms.txt
Bevor wir tiefer in die geschäftlichen Implikationen eintauchen, ist es wichtig zu verstehen, wo llms.txt im breiteren System der KI-Content-Strategien einzuordnen ist. Denn während alle über llms.txt sprechen, ist es nicht die einzige Lösung auf dem Markt.
Retrieval-Augmented Generation (RAG): Der aktuelle Standard
RAG hat sich als dominanter Ansatz zur Erweiterung von Sprachmodellen mit externem Wissen etabliert.
„RAG erweitert die bereits leistungsstarken Fähigkeiten von LLMs auf spezifische Domänen oder die interne Wissensbasis einer Organisation, und das alles, ohne dass das Modell neu trainiert werden muss.“ (Amazon)
Der Prozess funktioniert wie folgt: Wenn ein Benutzer eine Frage stellt, durchsucht das System eine Dokumentendatenbank, ruft relevante Informationen ab und speist diese zusammen mit der Anfrage in das LLM ein. Dies ist leistungsstark, bringt jedoch Kompromisse mit sich.
RAG-Herausforderungen:
- Abruflatenz, potenzielle Fehler bei der Dokumentenauswahl und erhöhte Systemkomplexität
- Erfordert anspruchsvolle Infrastruktur und fortlaufende Wartung
- Kann irrelevante oder veraltete Dokumente abrufen
- Komplexe Einrichtungs- und Abstimmungsanforderungen
Cache-Augmented Generation (CAG): Die aufkommende Alternative
Ein neuerer Ansatz, die Cache-Augmented Generation (CAG), gewinnt an Bedeutung. Anstatt Dokumente in Echtzeit abzurufen, lädt CAG alle relevanten Inhalte in das Kontextfenster des Modells vor und speichert die Ergebnisse im Cache.
„CAG nutzt die erweiterten Kontextfenster moderner großer Sprachmodelle (LLMs), indem es alle relevanten Ressourcen in den erweiterten Kontext des Modells vorlädt und dessen Laufzeitparameter zwischenspeichert.“ (GitHub)
Vorteile von CAG:
- Reduzierte Latenz – Eliminiert den Echtzeit-Abruf und ermöglicht eine schnellere Inferenz
- Vereinfachte Architektur
- Keine Abruffehler
- Konsistente Leistung
Die Rolle von llms.txt
Hier wird es interessant: llms.txt konkurriert nicht mit RAG oder CAG – es ist komplementär zu beiden. Während sich RAG und CAG darauf konzentrieren, wie KI-Systeme Informationen verarbeiten, konzentriert sich llms.txt darauf, wie diese Informationen überhaupt strukturiert und präsentiert werden.
Stellen Sie es sich so vor:
- RAG: „Lassen Sie mich nach relevanten Informationen suchen, um Ihre Frage zu beantworten.“
- CAG: „Lassen Sie mich die bereits geladenen Informationen verwenden, um Ihre Frage zu beantworten.“
- llms.txt: „Hier finden Sie genau die Informationen, die Sie benötigen.“
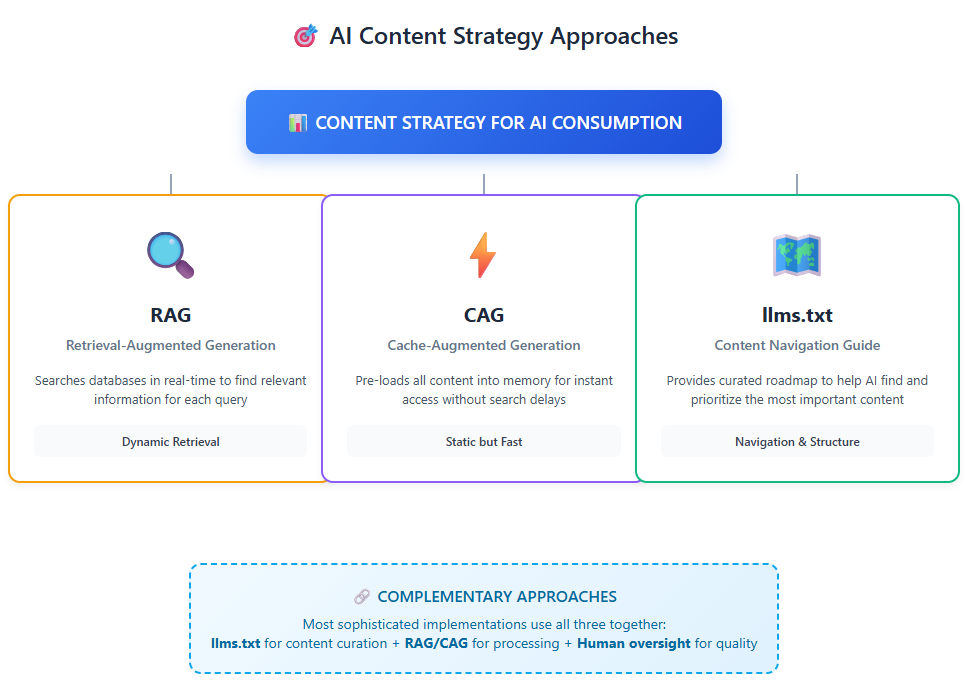
Die anspruchsvollsten Implementierungen nutzen alle drei Ansätze: llms.txt zur Organisation und Priorisierung von Inhalten, RAG oder CAG zur Verarbeitung von Anfragen und menschliche Aufsicht zur Qualitätssicherung.
Branchenakzeptanz: Frühe Signale und Marktrealität
Die Geschichte der llms.txt-Adoption liest sich wie eine klassische Tech-Erzählung: anfängliche Begeisterung, schnelle Plattformadoption, gefolgt vom unvermeidlichen Realitätscheck. Betrachten wir beide Seiten.
Die Erfolgsgeschichten
Die Adoptionskurve verschob sich im November 2024 dramatisch, als Mintlify, eine führende Dokumentationsplattform, eine strategische Entscheidung traf:
„Die Adoption blieb bis November eine Nische, als Mintlify die Unterstützung für /llms.txt auf allen von ihr gehosteten Dokumentationsseiten einführte. Praktisch über Nacht begannen Tausende von Dokumentationsseiten – darunter Anthropic und Cursor – llms.txt zu unterstützen.“
Dies war nicht nur eine Feature-Einführung – es war eine erzwingende Funktion, die fast sofort eine kritische Masse schuf.
Bemerkenswerte frühe Anwender:
Anthropic: Das vielleicht aussagekräftigste Adoptionssignal kommt vom Schöpfer von Claude. Ihre umfassende llms.txt-Implementierung organisiert alles von der API-Dokumentation bis zu Prompt-Bibliotheken in einer klaren Hierarchie.
Cloudflare: Ihre Implementierung zeigt, wie komplexe Unternehmen mit mehreren Diensten llms.txt effektiv nutzen können, indem sie die Dokumentation nach Dienstleistungsbereichen (AI Gateway, Workers usw.) organisieren.
Zapier: Konzentrierte ihr llms.txt auf API-Endpunkte und Automatisierungs-Workflows, speziell auf ihre Entwicklerzielgruppe ausgerichtet.
Der skeptische Realitätsabgleich
Doch sollten wir uns nicht zu früh freuen. Die Adoptionsgeschichte weist erhebliche Lücken auf.
John Mueller von Google, wohl eine der maßgeblichsten Stimmen zu Webstandards, gab folgende Einschätzung ab:
“Soweit mir bekannt, hat keiner der KI-Dienste angegeben, LLMs.TXT zu verwenden (und man kann anhand der Server-Logs erkennen, dass sie nicht einmal danach suchen)”.
Dies ist der entscheidende Punkt, den die meisten Berichte übersehen:
“Kein großer LLM-Anbieter unterstützt derzeit llms.txt. Weder OpenAI. Noch Anthropic. Noch Google”. (Ahrefs)
Gegenbeweise: Die Überwachungsdaten
Daten von Unternehmen, die sich auf KI-Optimierung spezialisiert haben, erzählen jedoch eine andere Geschichte. Profound, ein Unternehmen, das sich auf die Verfolgung von Generative Engine Optimization (GEO)-Metriken spezialisiert hat, hat Daten gesammelt, die zeigen, dass Modelle von Microsoft, OpenAI und anderen aktiv sowohl llms.txt- als auch llms-full.txt-Dateien crawlen und indizieren.
Die Diskrepanz deutet auf etwas Interessantes hin: Während große Anbieter sich offiziell noch nicht zu dem Standard bekannt haben, experimentieren ihre Systeme möglicherweise bereits damit.
Indikatoren für Marktdynamik
Jenseits der Adoptionsdebatten deuten mehrere Signale darauf hin, dass llms.txt Bestand haben wird:
- Entwicklungswerkzeuge: Integration in gängige Dokumentationsplattformen und Entwicklungsworkflows
- Community-Wachstum: Aktive Verzeichnisse zur Nachverfolgung von Implementierungen, Community-Diskussionen und Tool-Entwicklung
- Unternehmensfallstudien: Frühe Anwender berichten von positiven Erfahrungen und erweiterten Implementierungen
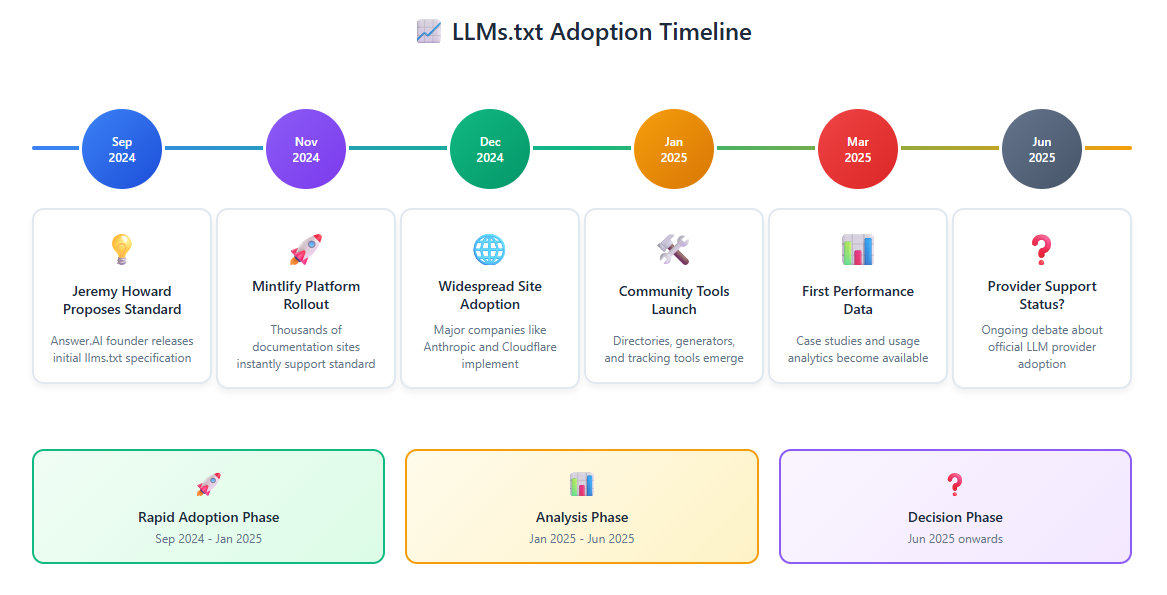
Das Muster ist jedem vertraut, der die Entwicklung von Webstandards verfolgt hat: Basisadoption, Plattformintegration, Community-Dynamik, gefolgt von einer eventuellen offiziellen Anerkennung. Ob llms.txt diesem Weg folgt, bleibt abzuwarten.
Strategische Geschäftsrelevanz
Kommen wir nun von der technischen Begeisterung zum Wesentlichen: Sollte Ihr Unternehmen llms.txt beachten, und wenn ja, was sollten Sie tun?
Das Risiko-Nutzen-Framework
Die Herausforderung bei jedem aufkommenden Standard besteht darin, den Early-Mover-Vorteil gegen das Risiko abzuwägen, auf das falsche Pferd zu setzen. Bei llms.txt ist die Rechnung ungewöhnlich günstig, da das Risiko minimal ist, während der potenzielle Nutzen erheblich ist.
Vorteile einer frühzeitigen Implementierung:
Das überzeugendste Argument ergibt sich aus der Erkenntnis, wohin sich die Content-Discovery entwickelt. “Heute verschafft die Zugänglichkeit für LLMs einen Wettbewerbsvorteil. Bald wird sie zur Grundvoraussetzung,” (Mintify).
Betrachten Sie die Implikationen: Wenn die Inhalte Ihrer Konkurrenten von KI-Modellen leicht konsumierbar sind, während Ihre Inhalte eine komplexe Analyse und Interpretation erfordern, welche Informationen werden Ihrer Meinung nach in KI-generierten Antworten zitiert?
Markenkontrolle in KI-Antworten: “Wenn Ihre Inhalte nicht im Docs-Bereich einer llms.txt-Datei enthalten sind, werden Ihre Marke und Ihre Narrative nicht gefunden,” (Profound). Dies ist keine Übertreibung – es ist eine logische Konsequenz, wie KI-Modelle die Informationsaufnahme priorisieren.
Einfachheit der Implementierung: Im Gegensatz zu RAG-Implementierungen, die eine erhebliche technische Infrastruktur erfordern, ist llms.txt erfrischend unkompliziert. Es ist eine Textdatei. Der technische Aufwand ist minimal, was es für Unternehmen jeder Größe zugänglich macht.
Die Risiken und Einschränkungen
Man sollte jedoch nicht so tun, als wäre dies eine Patentlösung.
Ungewisser ROI: Die ehrlichste Einschätzung ist, dass uns schlichtweg noch nicht genügend Daten vorliegen. Obwohl Early Adopters positive Signale melden, sind umfassende Leistungsstudien begrenzt. Wie eine Analyse feststellt: „Es gibt keine Belege dafür, dass llms.txt die KI-Retrieval verbessert, den Traffic steigert oder die Modellgenauigkeit erhöht.“
Risiko der Standardentwicklung: Jeder aufkommende Standard birgt das Risiko erheblicher Änderungen oder einer vollständigen Ablösung. Das Web ist übersät mit „Next Big Things“, die sich nie wirklich materialisiert haben: XHTML 2.0 sollte das Web-Markup revolutionieren, wurde aber zugunsten von HTML5 aufgegeben, das Semantic Web versprach maschinenlesbare Daten, blieb aber trotz jahrzehntelanger Arbeit weitgehend unerfüllt, und Web Components wurden als die Zukunft wiederverwendbarer HTML-Elemente gefeiert, haben aber aufgrund von Komplexität und Browser-Inkonsistenzen Schwierigkeiten bei der Akzeptanz.
Manipulationspotenzial: Wie beim frühen SEO besteht das Risiko, dass llms.txt zum Ziel von Manipulationen wird. Die Einfachheit, die es attraktiv macht, macht es auch anfällig für Spam und Manipulation. Wer sich noch an die Wild-West-Tage der frühen Suchmaschinenoptimierung erinnert, wird dieses Muster erkennen: Was als hilfreiches Signal beginnt, wird schnell zum Ziel von Missbrauch.
Wir haben das alles schon einmal erlebt – Keyword-Stuffing, das so eklatant war, dass Seiten aussahen, als wären sie von jemandem mit einem Schlaganfall geschrieben worden, unsichtbarer Text, vollgestopft mit Suchbegriffen, Linkfarmen, die die Gelben Seiten raffiniert aussehen ließen, und Meta-Keywords, die so mit irrelevanten Begriffen überladen waren, dass „Banane“ irgendwie dazu beitrug, für „Hypothekenrefinanzierung“ zu ranken. Der Zyklus ist vorhersehbar: Google führt einen Ranking-Faktor ein, clevere Leute nutzen ihn aus, die Qualität leidet, Google passt sich an, und das Wettrüsten geht weiter.
Bei llms.txt bestehen die gleichen Versuchungen: irrelevante Inhalte in den „Optional“-Bereich zu stopfen, irreführende Beschreibungen, die nicht mit dem tatsächlichen Inhalt übereinstimmen, oder gänzlich erfundene Ressourcenlisten zu erstellen. Der Unterschied besteht darin, dass Google zwar Jahrzehnte Zeit hatte, um eine ausgeklügelte Spam-Erkennung zu entwickeln, KI-Modelle, die llms.txt-Dateien konsumieren, jedoch noch lernen, Signal von Rauschen zu unterscheiden.
Branchenspezifische Überlegungen
Nicht jedes Unternehmen steht vor der gleichen Risiko-Nutzen-Abwägung. Der Wert von llms.txt variiert erheblich je nach Branche und Anwendungsfall.
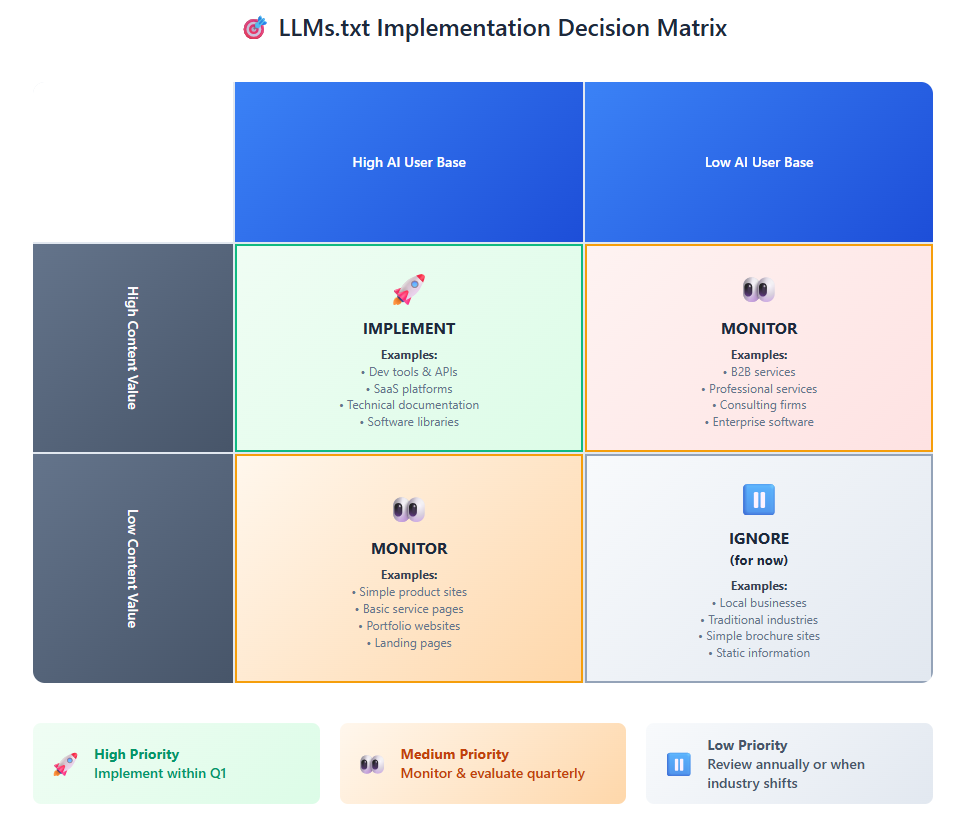
Sektoren mit hohem Wert:
SaaS und Entwicklertools: Wenn Ihr Publikum Entwickler, technische Entscheidungsträger oder Personen umfasst, die wahrscheinlich KI-Tools für Recherchen nutzen, ist die Implementierung von llms.txt praktisch obligatorisch. Diese Nutzer erhalten bereits Antworten von KI-Modellen, und Sie möchten, dass Ihre Informationen Teil dieser Antworten sind.
Professionelle Dienstleistungen: Branchen, die auf Fachwissen basieren – Beratung, Recht, Buchhaltung, Marketing – profitieren von einer klaren Informationshierarchie, die KI-Modellen hilft, Ihr Wissen genau zu verstehen und zu zitieren.
E-Commerce mit komplexen Produkten: Wenn Sie Produkte verkaufen, die Erklärungen, Vergleiche oder ein detailliertes Verständnis von Spezifikationen erfordern, kann eine strukturierte Darstellung über llms.txt die Art und Weise verbessern, wie KI-Modelle Ihre Angebote repräsentieren.
Vorsicht geboten:
Stark regulierte Branchen: Wo Inhaltskontrolle und Compliance von größter Bedeutung sind, kann die unsichere Akzeptanzlandschaft einen abwartenden Ansatz rechtfertigen.
Schnelllebige Informationen: Wenn sich Ihre Inhalte häufig ändern oder Echtzeitgenauigkeit erfordern, kann die statische Natur von llms.txt limitierend sein.
Kosten-Nutzen-Analyse
Betrachten wir die wirtschaftlichen Aspekte praktisch:
Implementierungskosten:
- Content-Audit und -Organisation: 2-5 Tage für die meisten Unternehmen
- Erstellung der initialen llms.txt: 1-2 Tage
- Laufende Wartung: 2-4 Stunden monatlich
Opportunitätskosten:
- Zeitaufwand für llms.txt im Vergleich zu anderen Optimierungsbemühungen
- Potenzielle Ablenkung von bewährten Strategien
Erwarteter Nutzen:
- Verbesserte KI-Zitationsraten und erhöhte Markensichtbarkeit
- Erhöhte Auffindbarkeit von Inhalten in KI-gestützten Tools
- Wettbewerbsvorteil in der Positionierung während der frühen Einführungsphase
Für die meisten Unternehmen überwiegen die Vorteile einer Implementierung die Kosten, insbesondere angesichts des geringen Ressourcenaufwands.
Implementierungsstrategie: Ein pragmatischer Ansatz
Angenommen, Sie haben sich für die Implementierung von llms.txt entschieden, erörtern wir nun, wie diese umgesetzt werden kann, ohne gängigen Fallstricken zu erliegen oder die Lösung zu überdimensionieren.
Checkliste für den Entscheidungsrahmen
Bevor Sie mit der Implementierung beginnen, durchlaufen Sie diese Bewertung, um einen strategischen Ansatz sicherzustellen:
Inhaltliche Vorbereitung:
- Verfügen wir über gut strukturierte, hierarchische Inhalte, die es wert sind, hervorgehoben zu werden?
- Können wir unsere wertvollsten Seiten und Ressourcen klar identifizieren?
- Sind unsere bestehenden Inhalte logisch organisiert, oder benötigen wir zuerst eine Umstrukturierung?
Ausrichtung auf die Zielgruppe:
- Nutzt unsere Zielgruppe KI-gestützte Suchwerkzeuge?
- Verpassen wir Chancen, wenn potenzielle Kunden unsere Kategorie mithilfe von KI recherchieren?
- Berichten unsere Vertriebsteams, dass Wettbewerber in KI-generierten Vergleichen erwähnt werden?
Ressourcenbewertung:
- Können wir 1-2 Wochen für die Erstimplementierung einplanen?
- Haben wir jemanden, der mit Markdown und grundlegenden Webdateien arbeiten kann?
- Können wir uns zu vierteljährlichen Überprüfungen und Aktualisierungen verpflichten?
Strategische Ausrichtung:
- Steht dies im Einklang mit unserer übergeordneten Content- und SEO-Strategie?
- Haben wir relevante Erfolgsmetriken für unser Unternehmen definiert?
- Sind wir bereit, geduldig auf Ergebnisse zu warten, während sich der Standard weiterentwickelt?
Implementierungsphasen
Anstatt dies als einmaliges Projekt zu betrachten, sollte llms.txt als ein iterativer Prozess angegangen werden, der sich im Laufe der Zeit verbessert.
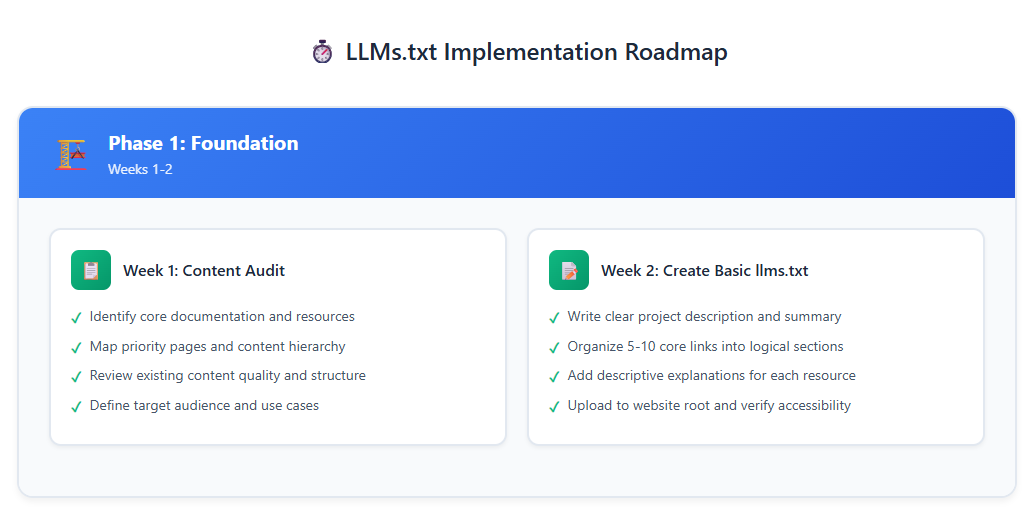
Phase 1: Grundlagen (Wochen 1-2)
Beginnen Sie mit den Grundlagen und stellen Sie schnell etwas live bereit:
- Content-Audit: Überprüfen Sie Ihre bestehenden Inhalte und identifizieren Sie:
- Kerndokumentation, die Ihr Produkt/Ihre Dienstleistung definiert
- Leistungsstarke Seiten, die Konversionen fördern
- Ressourcen, auf die Interessenten und Kunden häufig zugreifen
- API-Dokumentation, Leitfäden und technische Ressourcen (falls zutreffend
- Grundstruktur erstellen: Erstellen Sie Ihre anfängliche llms.txt mit:
- Klarer Projekt-/Firmenname und Beschreibung
- 5-10 Kern-Links, organisiert in logische Abschnitte
- Kurze, beschreibende Erläuterungen für jeden Link
- Strategische Nutzung des Abschnitts „Optional“ für sekundäre Ressourcen
- Implementierung: Laden Sie die Datei in das Stammverzeichnis Ihrer Website hoch und überprüfen Sie die Zugänglichkeit.
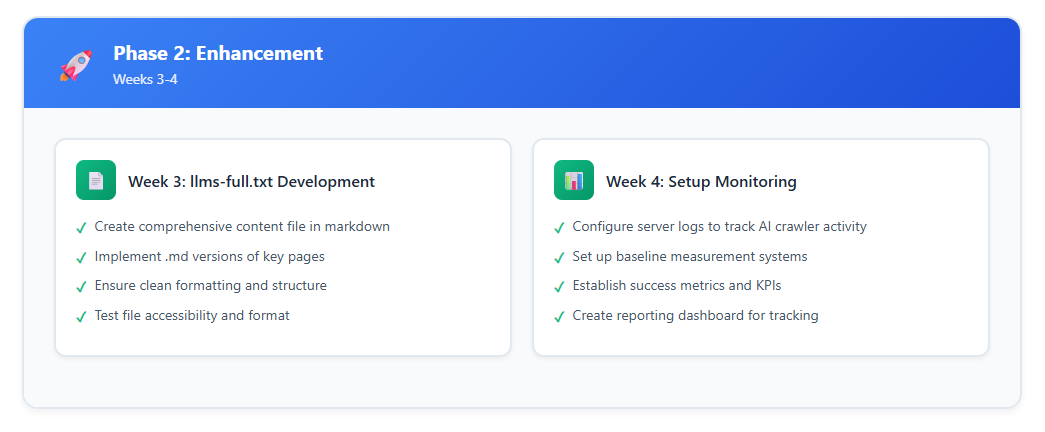
Phase 2: Erweiterung (Wochen 3-4)
Sobald die Grundlagen live sind, erweitern und verfeinern Sie:
- llms-full.txt entwickeln: Erstellen Sie die umfassende Version, die den vollständigen Inhalt im Markdown-Format enthält.
- .md-Versionen hinzufügen: Implementieren Sie Markdown-Versionen wichtiger Seiten (zugänglich durch Hinzufügen von .md zu URLs).
- Monitoring einrichten: Etablieren Sie ein Tracking für:
- KI-Crawler-Aktivität in Server-Logs
- Erwähnungen in KI-generierten Antworten
- Traffic-Muster von KI-gestützten Quellen
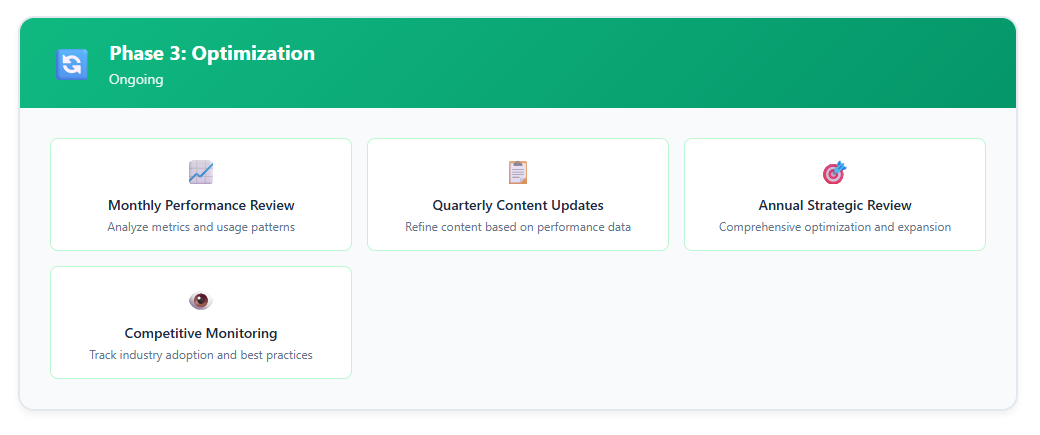
Phase 3: Optimierung (Laufend)
Wandeln Sie die Implementierung in einen Wettbewerbsvorteil um:
- Leistungsanalyse: Monatliche Überprüfung von Metriken und Nutzungsmustern
- Inhaltsoptimierung: Quartalsweise Aktualisierungen basierend auf Leistungsdaten und geschäftlichen Veränderungen
- Erweiterung: Schrittweise Einbindung zusätzlicher Ressourcen basierend auf Wert und Leistung
Integration in bestehende Arbeitsabläufe
Der Schlüssel zu einer nachhaltigen llms.txt-Implementierung besteht darin, sie zu einem integralen Bestandteil Ihrer regulären Content-Operationen zu machen und nicht zu einem separaten Projekt, das in Vergessenheit gerät.
Integration in das Content Management:
- Nehmen Sie llms.txt-Aktualisierungen in Ihre Content-Review-Zyklen auf
- Schulen Sie Content-Ersteller, die KI-Konsumption bei der Erstellung neuer Ressourcen zu berücksichtigen.
- Etablieren Sie klare Verantwortlichkeiten und Überprüfungsprozesse.
SEO-Koordination:
- Stellen Sie sicher, dass llms.txt die SEO-Strategie ergänzt und nicht mit ihr kollidiert.
- Verwenden Sie eine konsistente Botschaft und Positionierung sowohl bei der traditionellen als auch bei der KI-Optimierung.
- Koordinieren Sie das Keyword-Targeting und die Content-Themen.
Technische Implementierung:
- Minimaler Entwicklungsaufwand für die meisten Implementierungen.
- Erwägen Sie Automatisierung für größere Content-Volumen.
- Planen Sie Skalierbarkeit, wenn Ihre Content-Bibliothek wächst.
Erfolgsmessung
Die Herausforderung bei jedem aufkommenden Standard besteht darin, Erfolgsmetriken zu definieren, während sich die Landschaft noch entwickelt.
Quantitative Metriken:
- Server-Log-Analyse: Verfolgen Sie Anfragen an llms.txt und verwandte Dateien.
- KI-Zitationsverfolgung: Überwachen Sie Erwähnungen in KI-generierten Antworten (derzeit manuell, automatisierte Tools in Entwicklung).
- Traffic-Attribution: Identifizieren Sie Verweise von KI-gestützten Quellen.
- Suchleistung: Überwachen Sie Änderungen in der traditionellen Suchsichtbarkeit.
Qualitative Indikatoren:
- Genauigkeit der Markenerwähnung: Wie präzise stellen KI-Modelle Ihr Unternehmen dar?
- Wettbewerbspositionierung: Werden Sie im Kontext relevanter Wettbewerber erwähnt?
- Inhaltsqualität: Heben KI-Antworten Ihre wertvollsten Informationen hervor?
- Kundenfeedback: Erwähnen potenzielle Kunden, dass sie Sie über KI-Tools gefunden haben?
Frühwarnsysteme:
- Wettbewerbsmonitoring zur Verfolgung der Akzeptanz in Ihrer Branche
- Regelmäßige Tests von KI-Antworten auf kategoriebezogene Anfragen
- Feedback des Vertriebsteams zu Methoden der Interessentenrecherche
Die wichtigste Metrik, insbesondere in den frühen Phasen, ist schlichtweg, ob KI-Modelle Ihre wichtigsten Inhalte finden und korrekt darstellen können.
Zukunftsausblick: Vorbereitung auf die Evolution
Technologiestandards im KI-Bereich entwickeln sich rasant, und llms.txt bildet hier keine Ausnahme. Die Frage ist nicht, ob sich die Landschaft ändern wird – sondern wie schnell, und ob Ihr Unternehmen in der Lage sein wird, sich anzupassen.
Die technologische Trajektorie
Das Umfeld, in dem llms.txt agiert, verändert sich dramatisch.
„Magic.devs LTM-2-Mini verschiebt die Grenzen mit einem beeindruckenden Kontextfenster von 100 Millionen Tokens, was die Verarbeitung riesiger Datensätze wie ganzer Code-Repositories (bis zu 10 Millionen Zeilen Code) oder umfangreicher Dokumentensammlungen (entspricht 750 Romanen) ermöglicht“, (Coding Landscape).
Diese Erweiterung verändert das grundlegende Wertversprechen von Kuration versus Umfassendheit. Wenn ein KI-Modell das Äquivalent von Hunderten von Büchern in einer einzigen Abfrage verarbeiten kann, wird der Bedarf an sorgfältig kuratierten Inhaltszusammenfassungen weniger eindeutig.
Die Implikationen von CAG
Das Aufkommen von Cache-Augmented Generation als praktikable Alternative zu RAG eröffnet interessante Möglichkeiten für die Evolution von llms.txt. „Einfach alles in das Kontextfenster zu schieben und zu cachen ist einfacher, effizienter und funktioniert genauso gut (oder besser)“, (Prompt Hub).
Setzt sich dieser Trend fort, könnte sich llms.txt von einem Kurationstool zu einem Vorverarbeitungsstandard entwickeln, der dabei hilft zu definieren, wie Inhalte in erweiterten Kontextfenstern gecacht und priorisiert werden.
Signale der Standardentwicklung
Das vielsagendste Signal bezüglich der Zukunft von llms.txt stammt aus einer unerwarteten Quelle: Google hat eine llms.txt-Datei in sein neues Agents to Agents (A2A)-Protokoll aufgenommen. Dies deutet darauf hin, dass selbst wenn aktuelle LLM-Anbieter sich noch nicht offiziell zum Standard bekannt haben, das zugrunde liegende Konzept innerhalb des breiteren KI-Ökosystems Legitimität besitzt.
Weitere Evolutionsindikatoren, die zu beobachten sind:
- Industriestandardisierung: Bewegung hin zu formaler Spezifikation und Governance
- Plattformintegration: Integrierte Unterstützung von wichtigen CMS- und Dokumentationsplattformen
- Tool-Ökosystem: Entwicklung von Tools zur automatisierten Generierung, Überwachung und Optimierung
- Anbieterakzeptanz: Offizielle Unterstützungsbekundungen von großen LLM-Anbietern
Vorbereitung auf verschiedene Szenarien
Anstatt alles auf den Erfolg von llms.txt zu setzen, bereiten sich kluge Unternehmen auf mehrere Szenarien vor:
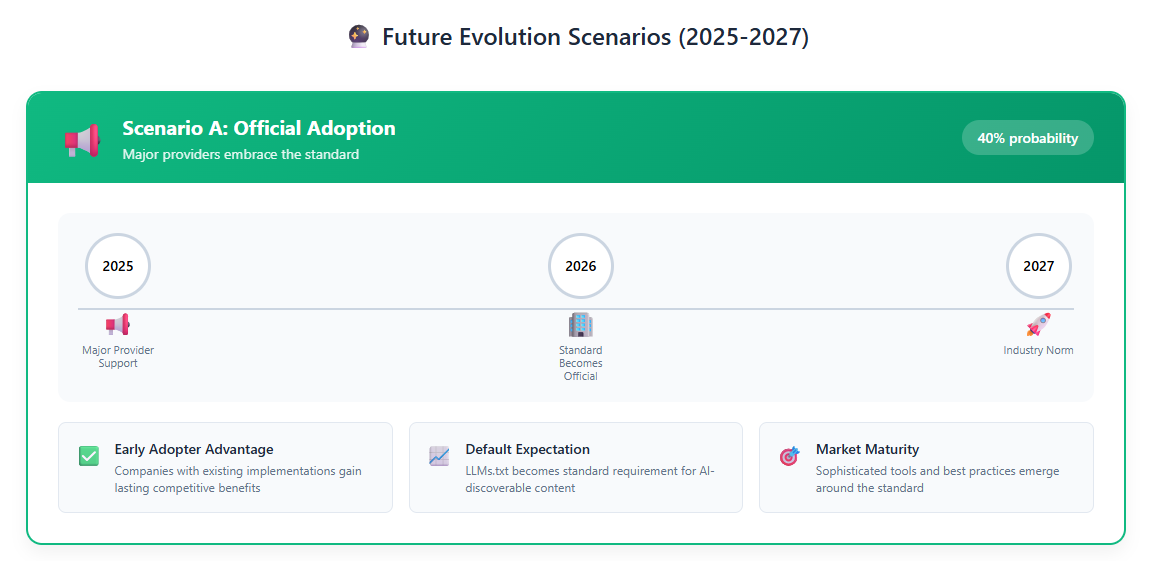
Szenario 1: Weitreichende Akzeptanz
Sollte llms.txt zu einem anerkannten Standard mit offizieller Anbieterunterstützung avancieren, werden Early Adopters erhebliche Wettbewerbsvorteile erzielen. Unternehmen mit gut strukturierten, umfassenden Implementierungen werden zu den primären Quellen für KI-generierte Antworten.
Szenario 2: Evolution und Weiterentwicklung
Das wahrscheinlichere Szenario sieht vor, dass sich llms.txt zu etwas Raffinierterem entwickelt – möglicherweise integriert mit semantischem Markup, automatischer Generierung oder dynamischer Aktualisierung. Die jetzt entwickelten Fähigkeiten zur Inhaltsstrukturierung und -kuratierung bleiben auch dann wertvoll, wenn sich die technische Implementierung ändert.
Szenario 3: Alternative Standards
Sollten konkurrierende Standards aufkommen oder sich bestehende Ansätze als überlegen erweisen, bleibt das zugrunde liegende Prinzip – Inhalte für KI-Systeme zugänglich zu machen – konstant. Der Aufwand, der in die Inhaltsorganisation und KI-freundliche Formatierung investiert wurde, überträgt sich auf jeden Standard, der sich letztendlich durchsetzt.
Strategische Positionierung angesichts von Unsicherheiten
Der Schlüssel zur Bewältigung dieser Unsicherheit liegt darin, Flexibilität zu bewahren und gleichzeitig nützliche Fähigkeiten aufzubauen:
In Grundlagen investieren: Konzentrieren Sie sich auf Inhaltsqualität, klare Struktur und logische Organisation, die jeder KI-Konsummethode zugutekommt.
Plattformunabhängig bleiben: Vermeiden Sie die Bindung an spezifische Tools oder Ansätze, die obsolet werden könnten.
Signale überwachen: Verfolgen Sie Adoptionsindikatoren, Anbietererklärungen und Wettbewerbsentwicklungen.
Traditionelle Strategien beibehalten: Geben Sie bewährte SEO- und Content-Marketing-Ansätze nicht auf, während Sie mit KI-Optimierung experimentieren.
Fazit und Empfehlungen
Lassen Sie uns einen Schritt zurücktreten und bewerten, was wir tatsächlich wissen, was wir vernünftigerweise vorhersagen können und welche Maßnahmen angesichts der aktuellen Lage sinnvoll sind.
Was wir mit Sicherheit wissen
KI-gestützte Suche und Content-Discovery ist kein Zukunftstrend – es ist eine gegenwärtige Realität, die täglich Millionen von Nutzern betrifft. Das traditionelle Modell der ausschließlichen Optimierung von Inhalten für menschliche Besucher und Googles Algorithmen ist zunehmend unzureichend.
KI-Modelle konsumieren und verarbeiten Webinhalte anders als Menschen oder traditionelle Such-Crawler. Sie profitieren von Struktur, Kuration und klaren Hierarchien, die die meisten Websites schlichtweg nicht bieten.
Die technische Hürde für die Implementierung von llms.txt ist minimal. Im Gegensatz zu komplexen KI-Implementierungen geht es hier im Wesentlichen um eine bessere Inhaltsorganisation und -präsentation.
Was weiterhin ungewiss ist
Ob llms.txt spezifisch zum dominanten Standard wird, ist noch eine offene Frage. Die Begeisterung von Entwicklern und Early Adopters ist vielversprechend, doch die offizielle Anbieterakzeptanz bleibt begrenzt.
Obwohl logisch, sind die Leistungsvorteile noch nicht durch umfassende Daten belegt. Frühe Indikatoren sind positiv, aber die Stichprobengröße bleibt gering.
Der Entwicklungspfad für den Standard selbst ist unklar. Was wir heute implementieren, könnte in 12-18 Monaten ganz anders aussehen.
Die pragmatische Antwort
Angesichts dieser Ausgangslage ist der vernünftigste Ansatz eine maßvolle Implementierung mit sorgfältiger Überwachung:
Sofortige Maßnahmen:
- Aktuelle Position bewerten: Prüfen Sie Ihre Inhaltsstruktur und identifizieren Sie hochwertige Ressourcen, die von einer besseren KI-Zugänglichkeit profitieren würden.
- Pilotimplementierung: Beginnen Sie mit einer grundlegenden llms.txt, die Ihre Kerninhalte abdeckt – betrachten Sie es als Experiment, nicht als Großprojekt.
- Monitoring etablieren: Richten Sie Tracking-Systeme ein, um die Aktivität von KI-Crawlern und die Erwähnungen von Inhalten zu messen.
- Branchenentwicklungen beobachten: Achten Sie auf Adoptionssignale in Ihrer spezifischen Branche und im Wettbewerbsumfeld.
Das übergeordnete strategische Gebot
Während sich die spezifische Mechanik von llms.txt entwickeln mag, wird das zugrunde liegende Prinzip Bestand haben.
Es geht hier nicht primär um llms.txt. Vielmehr geht es darum zu erkennen, dass sich die Content-Entdeckung grundlegend hin zu KI-vermittelten Interaktionen verschiebt. Unternehmen, die ihre Content-Strategien entsprechend anpassen, werden Sichtbarkeit und Einfluss behalten. Diejenigen, die dies nicht tun, riskieren, in einer KI-gestützten Suchlandschaft unsichtbar zu werden.
Abschließende Perspektive
Das überzeugendste Argument für die Implementierung von llms.txt ist nicht der potenzielle Nutzen, sondern der minimale Nachteil in Kombination mit der offensichtlichen Entwicklung des Content-Konsums. Selbst wenn dieser spezifische Standard keine universelle Akzeptanz findet, bleiben die für die Implementierung erforderlichen Fähigkeiten, Prozesse und die Content-Organisation wertvoll.
Wie ein Branchenbeobachter feststellte: “LLMS.txt trägt keine Inhalte zum Gedächtnis des Modells bei; es weist dem Modell lediglich an, wo es suchen soll, während es aktiv eine Antwort generiert.” Dies stellt eine vernünftige Investition dar, um Ihr Unternehmen in einer KI-zentrierten Welt auffindbar zu machen.
Die Frage ist nicht, ob KI die Content-Entdeckung neu gestalten wird – sie hat es bereits getan. Die Frage ist, ob Ihre Organisation bereit sein wird, wenn sich dieser Wandel beschleunigt.
Checkliste zur Implementierung:
- Bestehende Content-Struktur und -Qualität prüfen
- 5-10 Seiten und Ressourcen mit dem höchsten Wert identifizieren
- Eine grundlegende llms.txt mit klarer Hierarchie und Beschreibungen erstellen
- Monitoring für KI-Crawler-Aktivitäten implementieren
- Vierteljährliche Überprüfungen und Updates planen
- Wettbewerbsadoption und Branchensignale überwachen
- Traditionelles SEO parallel zu KI-Optimierungsbemühungen beibehalten
Einfach beginnen. Sorgfältig überwachen. Anpassen, während sich die Landschaft entwickelt.
Und denken Sie daran: Die beste Zeit, sich auf Veränderungen vorzubereiten, ist, bevor Sie gezwungen sind, darauf zu reagieren.
Bei ScaleMath unterstützen wir Unternehmen dabei, sich in der sich entwickelnden Landschaft der Suche und Content-Entdeckung zurechtzufinden. Wenn Sie strategische Beratung zu KI-Optimierung, Content Operations oder Wachstumsstrategien suchen, die den Menschen die Kontrolle über die Technologie geben, lassen Sie uns ins Gespräch kommen.